2022. 6. 13. 12:01ㆍCS/데이터베이스
①※ 물리적 데이터베이스 설계
- 논리적인 설계의 데이터 구조를 보조 기억 장치상의 파일(물리적인 데이터 모델)로 사상함
- 예상 빈도를 포함하여 데이터베이스 질의와 트랜잭션들을 분석함
- 데이터에 대한 효율적인 접근을 제공하기 위하여 저장 구조(storage structure)와 접근 방법(access method)들을 다룸 (물리적 데이터베이스 설계 파트에서 저장 구조, 접근 방법 두 가지가 중요하게 다뤄진다.) → access method 중에서 가장 optimal 한 method 가 random access(찾고자 하는 것이 저장소 내 어디에 있던 간에 찾아오는 시간이 동일) → flash memory가 이에 해당한다.
- 특정 DBMS의 특성을 고려하여 진행된다.
- 질의를 효과적으로 지원하기 위해서 인덱스 구조를 적절히 사용함
1. 보조 기억 장치
- 사용자가 원하는 데이터를 검색하기 위해서 DBMS는 디스크 상의 데이터베이스로부터 사용자가 원하는 데이터를 포함하고 있는 블록을 읽어서 주기억 장치로 가져옴 (주기억 장치(디스크)에 올라가야 컴퓨터가 읽을 수 있음)
- 데이터가 변경된 경우에는 블록들을 디스크에 다시 기록함
- 블록 크기는 512바이트부터 수 킬로바이트까지 다양함
- 전형적인 블록 크기는 4096바이트
- 각 파일은 고정된 크기의 블록들로 나누어져서 저장됨
- 디스크는 데이터베이스를 장기간 보관하는 주된 보조 기억 장치
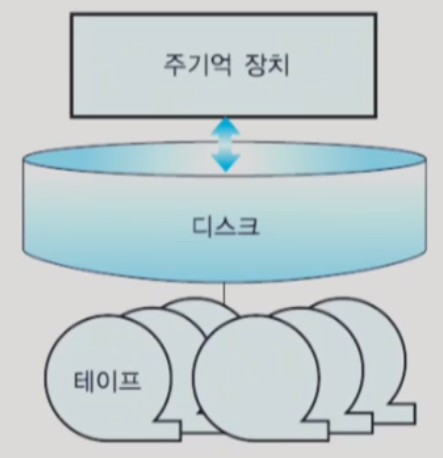
- 위 그림에서 빠져 있는 것이 주기억 장치와 디스크 사이에 flash memory와 cache memory가 존재한다.
※ 보조기억 장치의 종류
ⓛ 자기 디스크
- 디스크는 자기 물질로 이루어진 여러개의 판으로 이루어짐
- 각 면마다 디스크 헤드가 있음
- 각 판은 트랙과 섹터로 구분됨
- 정보는 디스크 표면 상의 동심원(트랙)을 따라 저장됨
- 여러 개의 디스크 면 중에서 같은 지름을 갖는 트랙들을 실린더라고 부름
- 블록은 한 개 이상의 섹터들로 이루어짐
- 디스크에서 임의의 블록을 읽어오거나 기록하는데 걸리는 시간은 탐구 시간(seek time), 회전 지연 시간(rotational delay), 전송 시간(transfer time)의 합 → 전송 시간 : 찾은 걸 메모리로 올리는데 걸리는 시간 // seek time은 variation이 큰 편임.
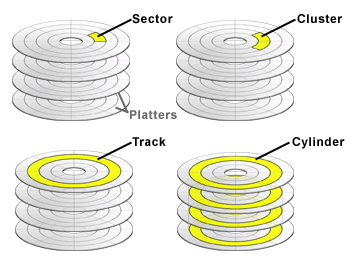
Q: 같은 섹터 라인 내에서 트랙에 따라 크기가 달라진다. → 바깥 쪽의 트랙에 포함되는 섹터는 저장을 많이 할 수 있을까?
A: 답은 바깥쪽이나 안쪽이나 같다 이다. 왜냐하면 디스크가 회전하면서 블록을 읽어오게 되는데 이 때 안쪽이나 바깥쪽이나 읽는데 걸리는 시간은 같기 때문이다.
* 한 relation을 한 cylinder 내에 저장하게 된다면 헤드가 움직이지 않고 찾아올 수 있다. (그만큼 seek time이 줄어들게 된다.)
2. 버퍼 관리와 운영 체제
- 디스크 입출력은 컴퓨터 시스템에서 가장 속도가 느린 작업이므로 입출력 횟수를 줄이는 것이 DBMS의 성능을 향상시키는데 매우 중요
- 가능하면 많은 블록들을 주기억 장치에 저장하거나, 자주 참조되는 블록들을 주기억 장치에 유지하면 블록 전송 횟수를 줄일 수 있음
- 버퍼는 디스크 블록들을 저장하는데 사용되는 주기억 장치 공간
- 버퍼 관리자는 운영 체제의 구성요소로서 주기억 장치 내에서 버퍼 공간을 할당하고 관리하는 일을 맡음
- 운영 체제에서 버퍼 관리를 위해 흔히 사용되는 LRU 알고리즘은 데이터베이스를 위해 항상 우수한 성능을 보이지는 않음 → 별도의 방법을 사용하기도 함.
3. 디스크 상에서 파일의 레코드 배치
- 릴레이션의 애트리뷰트는 고정 길이 또는 가변 길이의 필드로 표현됨
- 연관된 필드들이 모여서 고정 길이 또는 가변 길이의 레코드가 됨
- 한 릴레이션을 구성하는 레코드들의 모임이 파일이라고 부르는 블록들의 모임에 저장됨
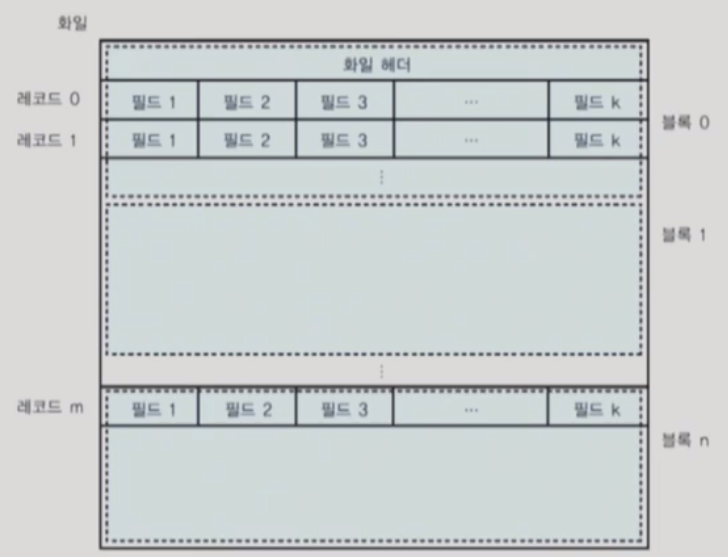
- 한 파일에 속하는 블록들이 반드시 인접해 있을 필요는 없음
- 어떻게 따로 떨어져있는 블록들이 같은 파일에 속한다는 것을 아는가 → Linked List의 형태로 각 블록에 저장된 포인터들로 다음 블록을 찾을 수 있기 때문이다.
- 인접한 블록들을 읽는 경우에는 탐구 시간과 회전 지연 시간이 들지 않기 때문에 입출력 속도가 빠르므로 블록들이 인접하도록 한 파일의 블록들을 재조직할 수 있음
※ BLOB(Binary Large Object)
- 이미지(GIF, JPG), 동영상(MPEG, AVI) 등 대규모 크기의 데이터를 저장하는데 사용된다.
- BLOB의 최대 크기는 MS SQL Server에서 2GB까지도 가능
※ 채우기 인수(fill factor)
- 각 블록에 레코드를 채우는 공간의 비율
- 나중에 레코드가 삽입될 때 기존의 레코드들을 이동하는 가능성을 줄이기 위해서. (새 레코드가 들어왔을 때, 빈 공간을 활용할 수 있다.)
ⓛ 고정 길이 레코드
- 레코드 i를 접근하기 위해서는 n*(i-1)+1의 위치에서 레코드를 읽음
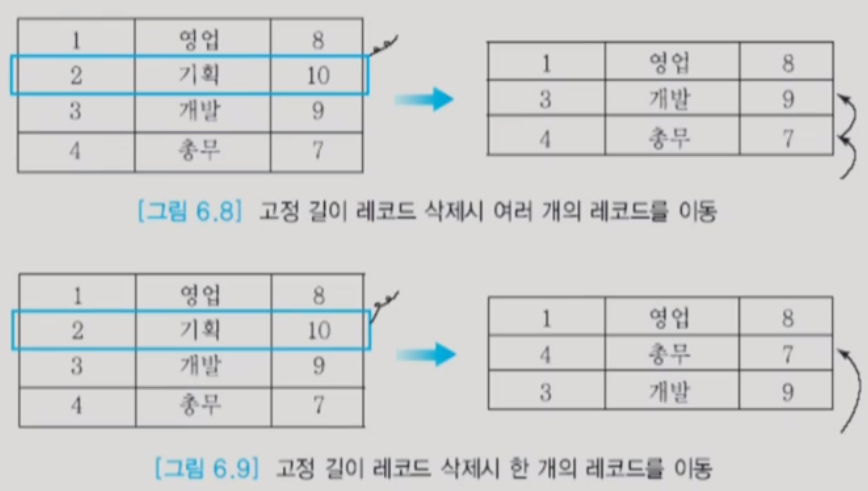
- 첫 번째 방법은 사용할 수 없음 -> 레코드가 많을 시 감당이 안된다.
※ 클러스터링(Clustering)
① 파일 내의 클러스터링(intra-file clustering)
- 한 파일 내에서 함께 검색될 가능성이 높은 레코드들을 디스크 상에서 물리적으로 가까운 곳에 모아두는 것

② 파일 간의 클러스터링(inter-file clustering)
- 논리적으로 연관되어 함께 검색될 가능성이 높은 두 개 이상의 파일에 속한 레코드들을 디스크 상에서 물리적으로 가까운 곳에 저장하는 것
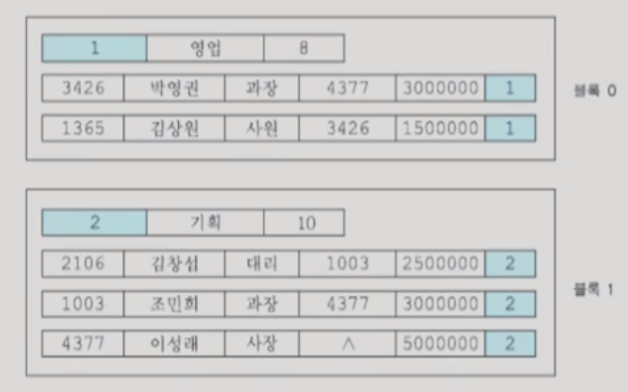
4. 파일 조직
※ 파일 조직의 유형
- 히프 파일(heap file)
- 순차 파일(sequential file)
- 인덱스된 순차 파일(indexed sequential file)
- 직접 파일(hash file)
1) 히프 파일(비순서 파일)
- 가장 단순한 파일 조직
- 일반적으로 레코드들이 삽입된 순서대로 파일에 저장됨
- 삽입: 새로 삽입되는 레코드는 파일의 가장 끝에 첨부됨 (insert는 중간에 끼어들어가기 때문에, insert보다는 append에 해당된다.)
- 검색: 원하는 레코드를 찾기 위해서는 모든 레코드들을 순차적으로 접근해야 함
- 삭제: 원하는 레코드를 찾은 후에 그 레코드를 삭제하고, 삭제된 레코드가 차지하던 공간을 재사용하지 않음
- 좋은 성능을 유지하기 위해서 히프 파일을 주기적으로 재조직할 필요가 있음 (삭제했을 때 공간이 많이 남으므로 비효율적, 주기적으로 compact하게 만들어줄 필요가 있음)
* 히프 파일의 성능
- 히프 파일은 질의에서 모든 레코드들을 참조하고, 레코드들을 접근하는 순서는 중요하지 않을 때 (select * from employee;)
- 특정 레코드를 검색하는 경우에는 히프 파일이 비효율적
- 히프 파일에 b개의 블록이 있다고 가정할 때, 원하는 블록을 찾기 위해서 평균적으로 b/2개의 블록을 읽어야 한다. (select title from employee where empno = 1365;)
- 다수의 레코드를 검색하는 경우에도 비효율적 -> 조건에 맞는 블록을 한 개 이상 검색했더라도 끝까지 조건이 맞는 블록을 가져와야 하기 때문에 b개의 블록을 모두 탐색해봐야 한다.

| 연산의 유형 | 시간 |
| 삽입 | 효율적 |
| 삭제 | 시간이 많이 소요 |
| 탐색 | 시간이 많이 소요 |
| 순서대로 검색 | 시간이 많이 소요 |
| 특정 레코드 검색 | 시간이 많이 소요 |
2. 순차 파일
- 레코드들이 하나 이상의 필드 값(애트리뷰트)에 따라 순서대로 저장된 파일
- 레코드들이 일반적으로 레코드의 탐색 키(search key) 값의 순서에 따라 저장됨
- 탐색 키는 순차 파일을 정렬하는데 사용되는 필드를 의미
- 삽입 연산은 삽입하려는 레코드의 순서를 고려해야 하기 때문에 시간이 많이 걸릴 수 있음
- 삭제 연산은 삭제된 레코드가 사용하던 공간을 빈 공간으로 남기기 때문에 히프 파일과 마찬가지로 주기적으로 순차 파일을 재조직해야 함
- 기본 인덱스가 순차 파일에 정의되지 않는 한 순차 파일은 데이터베이스 application을 위해 거의 사용되지 않음
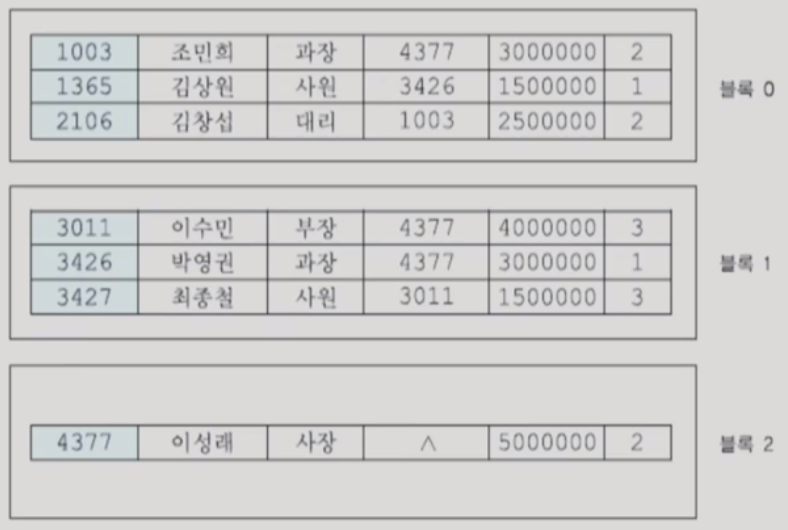
* 순차 파일의 성능
- EMPLOYEE 파일이 EMPNO의 순서대로 저장되어 있을 때 첫 번째 SELECT문은 이진 탐색을 이용할 수 있고, 두 번째 SELECT문의 WHERE절에 사용된 SALARY는 저장 순서와 무관하기 때문에 파일 전체를 탐색해야 함 (이진탐색의 시간 복잡도 -> log_2_n
- SELECT TITLE FROM EMPLOYEE WHERE EMPNO = 1365;
- SELECT EMPNAME, TITLE FROM EMPLOYEE WHERE SALARY >= 3000000 AND SALARY <= 4000000;
| 연산의 유형 | 시간 |
| 삽입 | 시간이 많이 소요 |
| 삭제 | 시간이 많이 소요 |
| 탐색 키를 기반으로 탐색 | 효율적 |
| 탐색 키가 아닌 필드를 사용하여 탐색 | 시간이 많이 소요 |

5. 단일 단계 인덱스
- 인덱스된 순차 파일은 인덱스를 통해서 임의의 레코드를 접근할 수 있는 파일
- 단일 단계 인덱스의 각 엔트리는 <탐색 키, 레코드에 대한 포인터(주소값)>
- 엔트리들은 탐색 키 값의 오름차순으로 정렬된다.
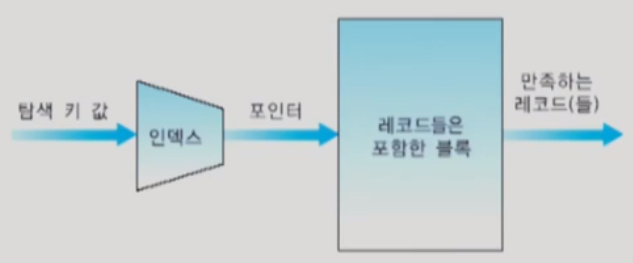
- 인덱스는 데이터 파일과는 별도의 파일에 저장된다.
- 인덱스의 크기는 데이터 파일의 크기에 비해 훨씬 작다. (요구되는 엔트리가 굉장히 작음)
- 하나의 파일에 여러 개의 인덱스를 정의할 수 있음
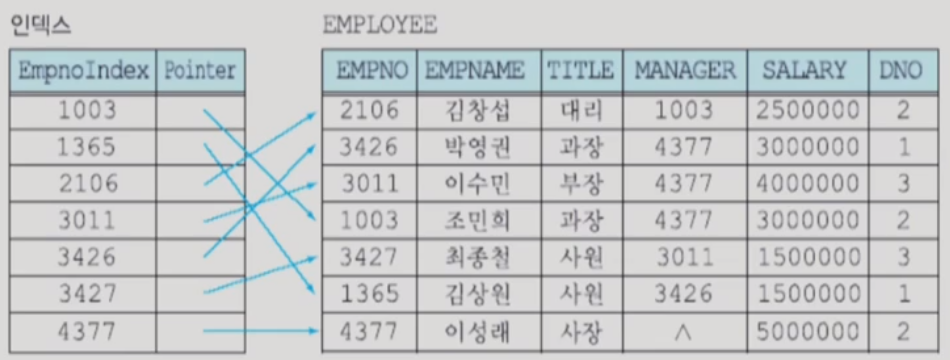
- 카디널리티가 낮은 필드를 가지고 인덱스를 만드는 것은 어리석은 방법이다.
- 인덱스가 정의된 필드를 탐색 키 라고 부름
- 탐색 키의 값들은 후보 키처럼 각 tuple마다 반드시 고유하지는 않다.
- 키를 구성하는 애트리뷰트 뿐만 아니라 어떤 애트리뷰트도 탐색 키로 사용될 수 있음
- 인덱스의 엔트리들은 탐색 키 값이 오름차순으로 저장되어 있으므로 이진 탐색을 활용할 수 있음
※ 기본 인덱스(primary index) ← primary key를 가지고 만든 index
- 탐색 키가 데이터 파일의 기본 키인 인덱스를 기본 인덱스라고 부름
- 기본 인덱스는 기본 키의 값에 따라 정렬된 데이터 파일에 대해 정의됨
- 기본 인덱스는 흔히 희소(sparse) 인덱스로 유지할 수 있음
- 각 릴레이션마다 최대한 한 개의 기본 인덱스를 가질 수 있음
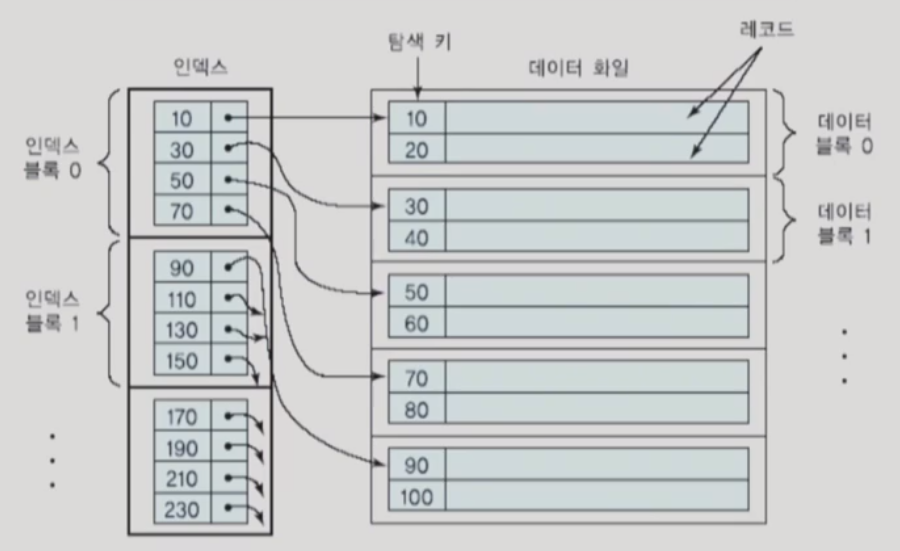
- 위의 그림에서는 블록 중 첫 번째로 있는 값만 가져왔으므로 희소 인덱스라고 하고, 그냥 모든 값을 가져왔다면 그것은 밀집(dense) 인덱스가 된다.
- 보통은 위 그림과 같은 방법을 사용한다. 블록 중 첫 번째의 레코드의 pk를 가져와서 인덱스의 크기를 줄일 수 있다. (블록킹 인수와 비례해서 줄일 수 있다는 말)
- 이 방법을 사용할 때 데이터 파일은 sorting되어 있어야 한다.

※ 클러스터링 인덱스(clustering index)
- 탐색 키 값에 따라 정렬된 데이터 파일에 대해 정의됨
- 각각의 상이한 키 값마다 하나의 인덱스 엔트리가 인덱스에 포함됨
- 범위 질의에 유용
- 범위의 시작 값에 해당하는 인덱스 엔트리를 먼저 찾고, 범위에 속하는 인덱스 엔트리들을 따라가면서 레코드들을 검색할 때 디스크에서 읽어오는 블록 수가 최소화됨
- 어떤 인덱스 엔트리에서 참조되는 데이터 블록을 읽어오면 그 데이터 블록에 들어 있는 대부분의 레코드들은 범위를 만족함

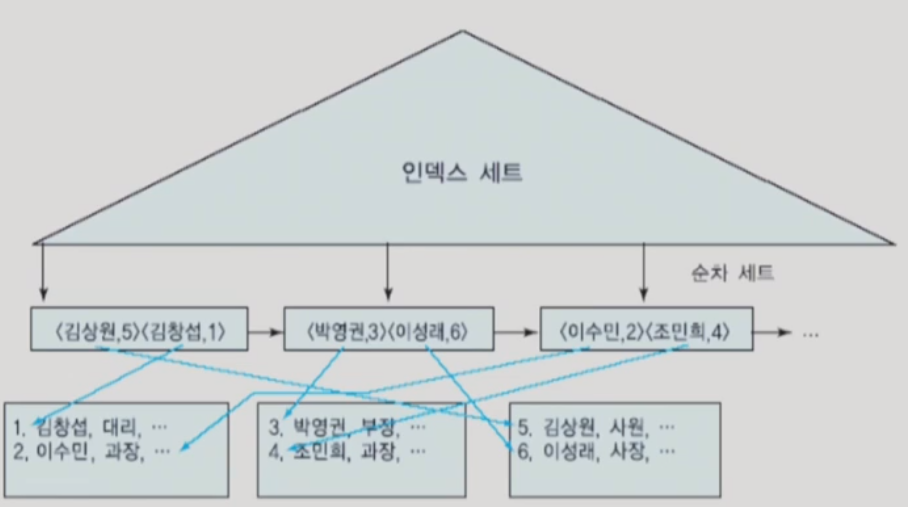

※ 보조 인덱스(secondary index)
- 한 파일은 기껏해야 한 가지 필드들의 조합에 대해서만 정렬될 수 있음
- 보조 인덱스는 탐색 키 값에 따라 정렬되지 않은 데이터 파일에 대해 정의됨
- 보조 인덱스는 일반적으로 밀집 인덱스이므로 같은 수의 레코드들을 접근할 때 보조 인덱스를 통하면 기본 인덱스를 통하는 경우보다 디스크 접근 횟수가 증가할 수 있음
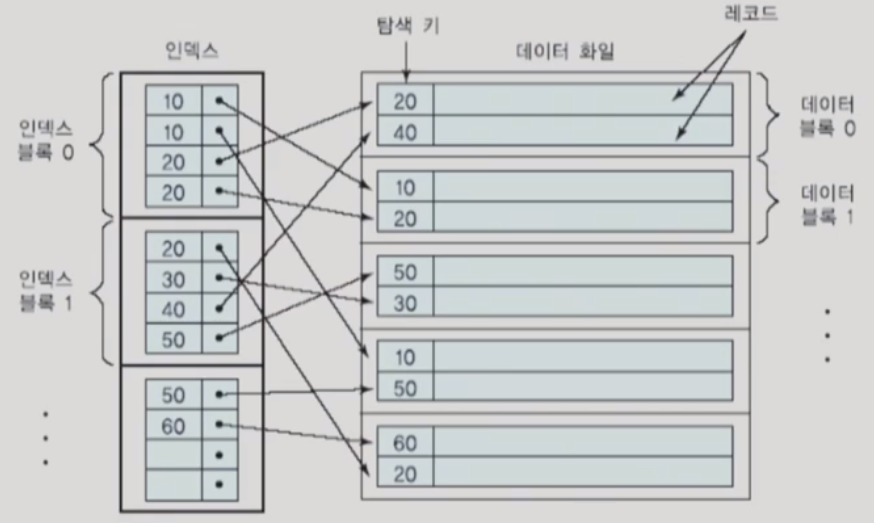

※ 희소 인덱스와 밀집 인덱스의 비교 (→ 클러스터링은 한 개를 기준으로밖에 할 수 없다.)
- 희소 인덱스는 각 데이터 블록마다 한 개의 엔트리를 갖고, 밀집 인덱스는 각 레코드마다 한 개의 엔트리를 가짐
- 레코드의 길이가 블록 크기보다 훨씬 작은 일반적인 경우에도 희소 인덱스의 엔트리 수가 밀집 인덱스의 엔트리 수보다 훨씬 적음
- 희소 인덱스는 일반적으로 밀집 인덱스에 비해 인덱스 단계 수가 1 정도 적으므로 인덱스 탐색 시 디스크 접근 수가 1만큼 적을 수 있음
- 희소 인덱스는 밀집 인덱스에 비해 모든 갱신과 대부분의 질의에 대해 더 효율적
- 그러나 질의에서 인덱스가 정의된 애트리뷰트만 검색(예를 들어, count 질의) 하는 경우에는 데이터 파일을 접근할 필요 없이 인덱스만 접근해서 질의를 수행할 수 있으므로 밀집 인덱스가 희소 인덱스보다 유리
- 한 파일은 한 개의 희소 인덱스와 다수의 밀집 인덱스를 가질 수 있음
'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 뷰와 시스템 카탈로그 (0) | 2022.06.18 |
|---|---|
| [데이터베이스] 릴레이션 정규화 (0) | 2022.06.17 |
| [데이터베이스] 물리적 데이터베이스 설계(2) (0) | 2022.06.16 |
| [데이터베이스] ER 스키마를 관계 모델의 Relation으로 사상 (0) | 2022.06.13 |
| [데이터베이스] 데이터베이스 설계와 ER 모델 (0) | 2022.06.10 |