[데이터베이스] 트랜잭션
2022. 6. 19. 12:57ㆍCS/데이터베이스
1. 트랜잭션 개요
- 항공기 예약, 은행, 신용 카드 처리, 대형 할인점 등에서는 대규모 데이터베이스를 수백, 수천 명 이상의 사용자들이 동시에 접근함
- 많은 사용자들이 동시에 데이터베이스의 서로 다른 부분 또는 동일한 부분을 접근하면서 데이터베이스를 사용함
- 동시성 제어(concurrency control) : 동시에 수행되는 트랜잭션들이 데이터베이스에 미치는 영향은 이들을 순차적으로 수행하였을 때 데이터베이스에 미치는 영향과 같도록 보장, 다수 사용자가 데이터베이스를 동시에 접근하도록 허용하면서 데이터베이스의 일관성을 유지함.
- 정보 시스템 평가 : TPS(Transaction Per Second)로 평가
- 회복(recovery) : 데이터베이스를 갱신하는 도중에 시스템이 고장나도 데이터베이스의 일관성을 유지함
※ 데이터베이스 시스템 환경에서 흔히 볼 수 있는 몇 가지 응용의 예
1.

- 이 때 500명 전원의 급여가 수정되거나 한 명의 급여도 갱신되지 않도록 DBMS가 보장해야 함 (원자성)
- 320번째 사원까지 수정한 상태에서 컴퓨터 시스템이 다운된 후에 재기동되었을 때 DBMS는 어떻게 대응해야 하는가?
- DBMS가 추가로 정보를 유지하지 않는다면 DBMS가 재기동된 후에 어느 직원의 투플까지 수정되었는가를 알 수 없음 → 로그(log) 유지 → 로그를 보고 회복을 해준다.

2.

- 두 개의 UPDATE문을 사용하여, 하나의 UPDATE문에서는 정미림의 잔액을 100,000원 감소시키고, 또 다른 UPDATE문에서는 안명석의 잔액을 100,000원 증가시킴
- 첫 번째 UPDATE문을 수행한 후에 두 번째 UPDATE문을 수행하기 전에 컴퓨터 시스템이 다운되면 재기동한 후에 DBMS가 어떻게 대응해야 하는가?
- 위의 두 개의 UPDATE문은 둘 다 완전하게 수행되거나 한 UPDATE문도 수행되어서는 안되도록, 즉 하나의 트랜잭션(단위)처럼 DBMS가 보장해야 함.
- 기본적으로 각각의 SQL문이 하나의 트랜잭션으로 취급됨
- 두 개 이상의 SQL문들을 하나의 트랜잭션으로 취급하려면 사용자가 이를 명시적으로 표시해야 함
3. 트랜잭션은 한 몸처럼 움직여야 한다. (중간의 SQL문이 얼마나 많던간에)


- DBMS의 중요 의무는 commit된 데이터에 대해서는 어떠한 일이 있어도 데이터를 보장해준다.
- Abort는 철회, 취소의 의미를 갖고, commit은 처리, 완료의 의미를 갖는다.
- 만일 SQL문 (2)를 수행하고 SQL문 (3)을 수행하기 전에 컴퓨터 시스템이 다운되고 재기동한 후에 DBMS가 어떻게 대응해야 하는가?
- 위의 세 개의 SQL문이 모두 완전하게 수행되거나 하나도 수행되어서는 안되도록, 즉 하나의 트랜잭션(단위)처럼 DBMS가 취급해야 함
- DBMS는 각 SQL문의 의미를 알 수 없으므로 하나의 트랜잭션으로 취급해야 하는 SQL문들의 범위를 사용자가 명시적으로 표시해야 함
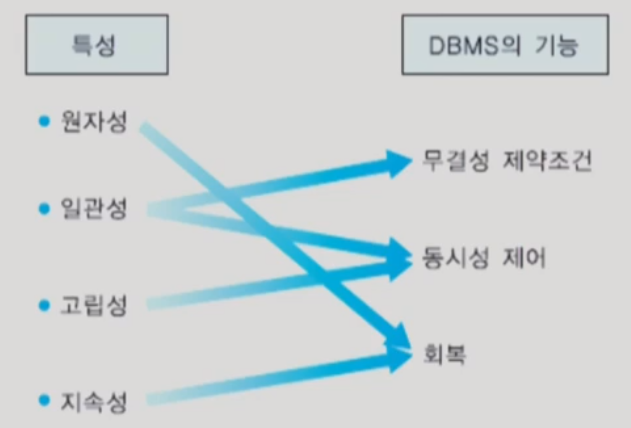
※ 트랜잭션의 특성(ACID 특성)
1. 원자성 (Atomicity)
- 한 트랜잭션 내의 모든 연산들이 완전히 수행되거나 전혀 수행되지 않음(all or nothing)을 의미
- DBMS의 회복 모듈은 시스템이 다운되는 경우에, 부분적으로 데이터베이스를 갱신한 트랜잭션의 영향을 취소함으로써 트랜잭션의 원자성을 보장함
- 완료된 트랜잭션이 갱신한 사항은 트랜잭션의 영향을 재수행(REDO)함으로써 트랜잭션의 원자성을 보장함
2. 일관성(Consistency)
- 어떤 트랜잭션이 수행되기 전에 데이터베이스가 일관된 상태를 가졌다면 트랜잭션이 수행된 후에 데이터베이스는 또 다른 일관된 상태를 가짐
- 트랜잭션이 수행되는 도중에는 데이터베이스가 일시적으로 일관된 상태를 갖지 않을 수 있음

3. 고립성(Isolation)
- 한 트랜잭션이 데이터를 갱신하는 동안 이 트랜잭션이 완료되기 전에는 갱신 중인 데이터를 다른 트랜잭션들이 접근하지 못하도록 해야 함
- 다수의 트랜잭션들이 동시에 수행되더라도 그 결과는 어떤 순서에 따라 트랜잭션들을 하나씩 차례대로 수행한 결과와 같아야 함
- DBMS의 동시성 제어 모듈이 트랜잭션의 고립성을 보장함
- DBMS는 응용들의 요구사항에 따라 다양한 고립 수준(isolation level)을 제공함
4. 지속성(Durability)
- 일단 한 트랜잭션이 완료되면 이 트랜잭션이 갱신한 것은 그 후에 시스템에 고장이 발생하더라도 손실되지 않음
- 완료된 트랜잭션의 효과는 시스템이 고장난 경우에도 데이터베이스에 반영됨
- DBMS의 회복 모듈은 시스템이 다운되는 경우에도 트랜잭션의 지속성을 보장함
* 트랜잭션의 완료(commit)
- 트랜잭션에서 변경하려는 내용이 데이터베이스에 완전하게 반영됨
- SQL 구문상으로 COMMIT WORK
* 트랜잭션의 철회(abort)
- 트랜잭션에서 변경하려는 내용이 데이터베이스에 일부만 반영된 경우에는 원자성을 보장하기 위해서, 트랜잭션이 갱신한 사항을 트랜잭션이 수행되기 전의 상태로 되돌림
- SQL 구문상으로 ROLLBACK WORK → UNDO연산 필요(어렵다, old value를 로그에 기록해 두어야 함)

2. 동시성 제어
- 대부분의 DBMS들은 다수 사용자용
- 여러 사용자들이 동시에 동일한 테이블을 접근하기도 함
- DBMS의 성능을 높이기 위해 여러 사용자의 질의나 프로그램들을 동시에 수행하는 것이 필수적
- 동시성 제어 기법은 여러 사용자들이 다수의 트랜잭션들을 동시에 수행하는 환경해서 부정확한 결과를 생성할 수 있는, 트랜잭션들 간의 간섭이 생기지 않도록 함
- 직렬 스케줄(serial schedule) : 여러 트랜잭션들의 집합을 한 번에 한 트랜잭션씩 차례대로 수행함 (병렬이 아님)
- 비직렬 스케줄(non-serial schedule) : 여러 트랜잭션들을 동시에 수행함 (일관성을 보장하지 못함)
- 직렬가능(serializable) : 비직렬 스케줄의 결과가 어떤 직렬 스케줄의 수행 결과와 동등함 → 목표가 된다.
※ 데이터베이스 연산
- Input(X) 연산은 데이터베이스 항목 X를 포함하고 있는 블록을 주기억 장치의 버퍼로 읽어들임
- Output(X) 연산은 데이터베이스 항목 X를 포함하고 있는 블록을 디스크에 기록함
- read_item(X) 연산은 주기억 장치 버퍼에서 데이터베이스 항목 X의 값을 프로그램 변수 X로 복사함
- write_item(X) 연산은 프로그램 변수 X의 값을 주기억 장치 내의 데이터베이스 항목 X에 기록함

※ 동시성 제어를 하지 않고 다수의 트랜잭션을 동시에 수행할 때 생길 수 있는 문제
- 갱신 손실(lost update) : 수행 중인 트랜잭션이 갱신한 내용을 다른 트랜잭션이 덮어씀으로써 갱신이 무효가 되는 것
- 오손 데이터 읽기(dirty read) : 완료되지 않은 트랜잭션이 갱신한 데이터를 읽는 것 (rollback이 연쇄적으로 발생한다. (cascade rollback, 연쇄 복귀))
- 반복할 수 없는 읽기(unrepeatable read) : 한 트랜잭션이 동일한 데이터를 두 번 읽을 때 서로 다른 값을 읽는 것 (다른 트랜잭션이 데이터에 접근해 업데이트 해버림. isolation level을 지키지 않았다.)
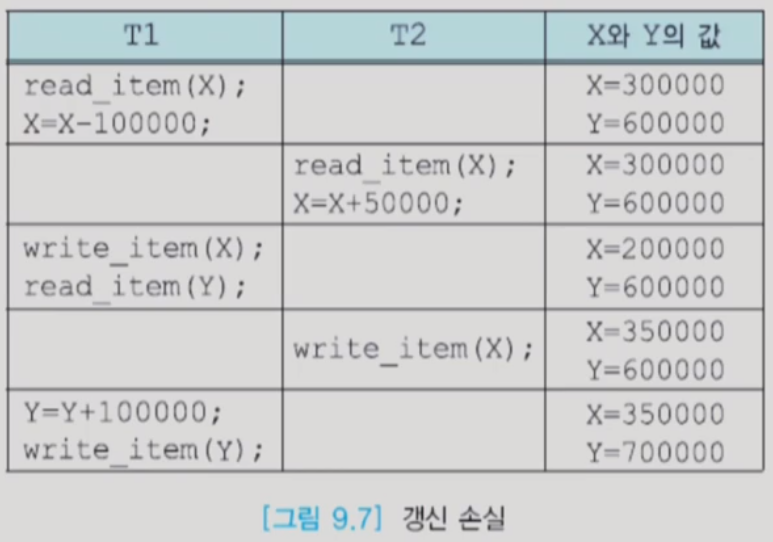
- T1이 300000에서 100000을 뺀 결과가 사라진 셈이다. (T2에서 50000이 더한 결과만 남음)
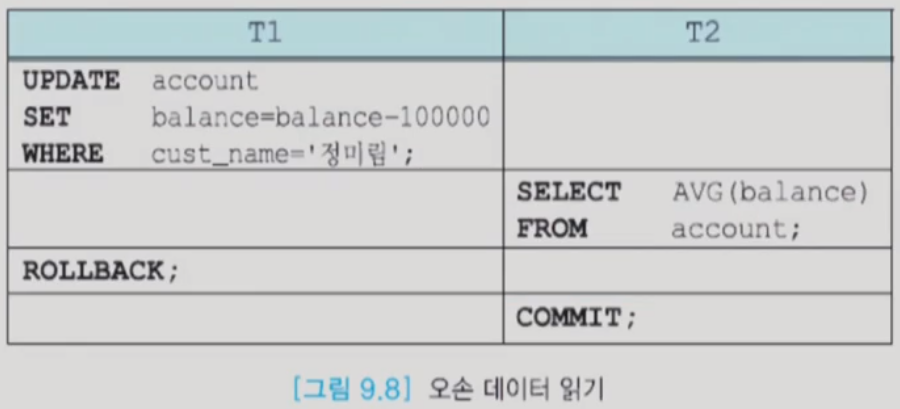
- 평균값을 구할 때 롤백이 일어난 뒤의 평균을 구해야 했는데 롤백이 되지 않은 값을 COMMIT한 것은 잘못되었음
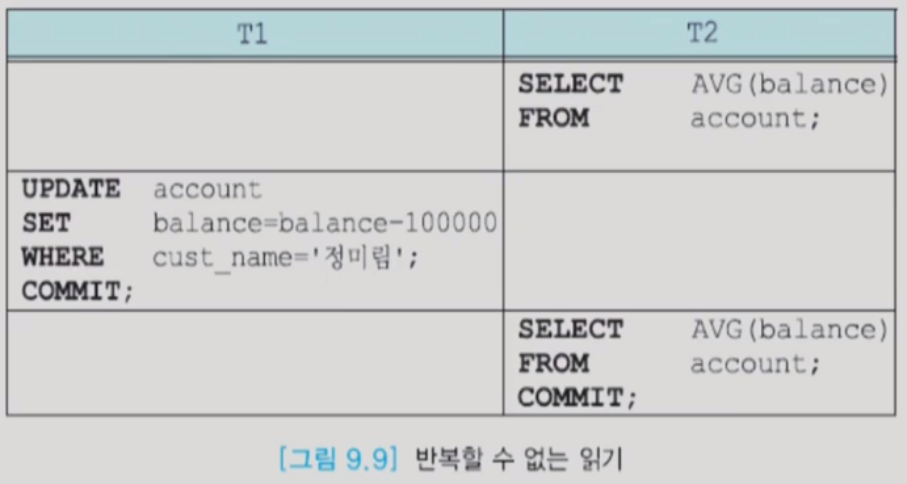
- 스케줄링 알고리즘 자체가 complexity가 높고, optimal한 알고리즘을 찾는 것도 overhead가 크다.
- 모든 트랜잭션에 대해 protocol(규약)을 정한 뒤, 이 규약을 지키기만 하면 동시성 제어가 되는 방식을 택함
- 공유 자원(data sharing)에서 문제가 생긴다. (서로 공유 자원에 대해 업데이트하려고 할 때 conflict가 생긴다.)
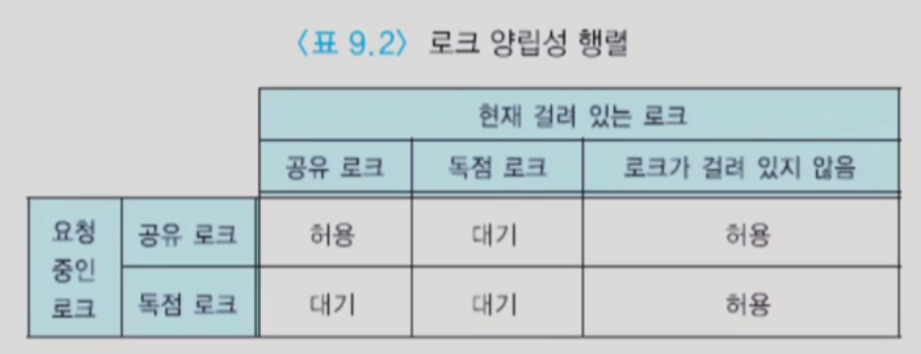
※ 로킹(locking)
- 데이터 항목을 로킹하는 개념은 동시에 수행되는 트랜잭션들의 동시성을 제어하기 위해서 가장 널리 사용되는 기법
- 로크(lock)는 데이터베이스 내의 각 데이터 항목과 연관된 하나의 변수
- 각 트랜잭션이 수행을 시작하여 데이터 항목을 접근할 때마다 요청한 로크에 관한 정보는 로크 테이블(lock table) 등에 유지됨
- 트랜잭션에서 갱신을 목적으로 데이터 항목에 접근할 때는 독점 로크(X-lock, eXclusive lock)를 요청함
- 트랜잭션에서 읽을 목적으로 데이터 항목을 접근할 때는 공유 로크(S-lock, Shared lock)를 요청함
- 트랜잭션이 데이터 항목에 대한 접근을 끝낸 후에 로크를 해제(unlock)함
※ 2단계 로킹 프로토콜(2-phase locking protocol)
- 로크를 요청하는 것과 로크를 해제하는 것이 2단계로 이루어짐
- 로크 확장 단계가 지난 후에 로크 수축 단계에 들어감
- 일단 로크를 한 개라도 해제하면 로크 수축 단계에 들어감
- 자기가 사용할 데이터 전체에 lock을 걸 때까지는 해제를 못한다. 로크를 걸 게 없게 되었을 때부터 해제를 할 수 있다. 마찬가지로, 해제하는 단계에서는 새로 lock을 걸 수 없다.

- 로크 확장 단계(1단계) : 로크 확장 단계에서는 트랜잭션이 데이터 항목에 대하여 새로운 로크를 요청할 수 있지만, 보유하고 있던 로크를 하나라도 해제할 수 없음
- 로크 수축 단계(2단계) : 로크 수축 단계에서는 보유하고 있던 로크를 해제할 수 있지만 새로운 로크를 요청할 수 없음, 로크 수축 단계에서는 로크를 조금씩 해제할 수 있고, 트랜잭션이 완료 시점에 이르렀을 때 한꺼번에 모든 로크를 해제할 수도 있음 (일반적으로 한꺼번에 해제하는 방식 필요)
- 로크 포인트(lock point)는 한 트랜잭션에서 필요로 하는 모든 로크를 걸어놓은 시점

- 위처럼 한꺼번에 해제함으로써 cascade rollback 등의 문제를 원천적으로 차단할 수 있다.
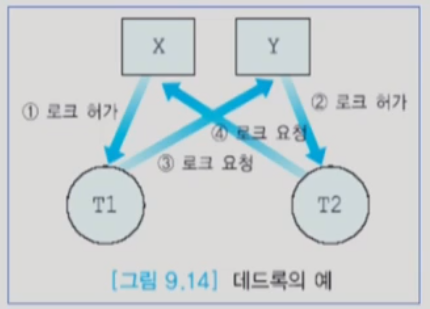
※ 데드록(deadlock)
- 2단계 로킹 프로토콜에서는 데드록이 발생할 수 있음
- 데드록은 두 개 이상의 트랜잭션들이 서로 상대방이 보유하고 있는 lock를 요청하면서 기다리고 있는 상태를 말함
- 데드록을 해결하기 위해서는 데드록을 방지하는 기법이나, 데드록을 탐지하고 희생자를 선정하여 데드록을 푸는 기법 등을 사용함 (victim을 process kill)
※ 다중 로크 단위(multiple granularity)
- 대부분의 트랜잭션들이 소수의 투플들을 접근하는 데이터베이스 응용에서는 투플 단위로 로크를 해도 로크 테이블을 다루는 시간이 오래 걸리지 않음
- 트랜잭션들이 많은 투플을 접근하는 데이터베이스 응용에서 투플 단위로만 로크를 한다면 로크 테이블에서 로크 충돌을 검사하고, 로크 정보를 기록하는 시간이 오래 걸림
- 트랜잭션이 접근하는 투플의 수에 따라 로크를 하는 데이터 항목의 단위를 구분하는 것이 필요
- 한 트랜잭션에서 로크할 수 있는 데이터 항목이 두 가지 이상 있으면 다중 로크 단위라고 말함
- 데이터베이스에서 로크할 수 있는 단위로는 데이터베이스, 릴레이션, 디스크 블록, 투플 등
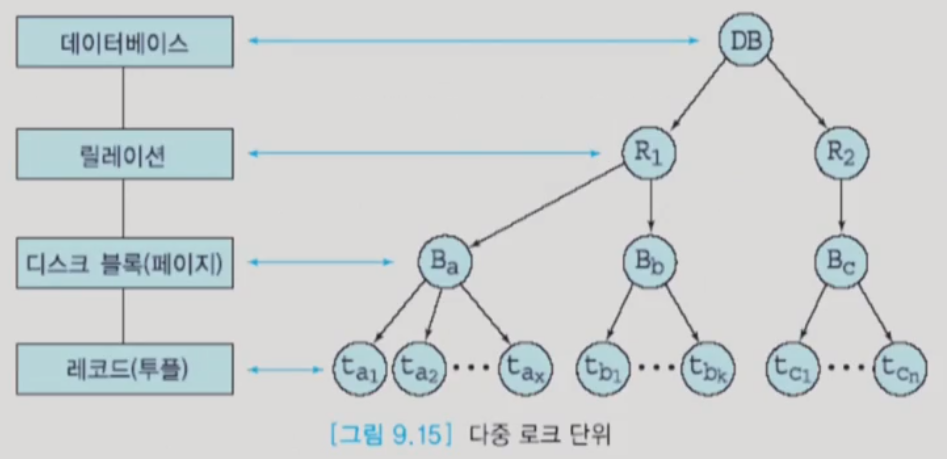
- 일반적으로 DBMS는 각 트랜잭션에서 접근하는 투플 수에 따라 자동적으로 로크 단위를 조정함
- 로크 단위가 작을수록 로킹에 따른 오버헤드는 증가함
- 로크 단위가 작을수록 동시성의 정도는 증가함 (수많은 트랜잭션들의 동시성)
※ 팬텀 문제(phantom problem, 보이지 않는 문제)

- 현재 릴레이션에 존재하지 않는 투플까지 lock을 걸 수는 없다. (유령의 투플 문제 발생)
- DNO가 1인 현 릴레이션의 투플들에 lock을 거는 것이 아닌, DNO가 1인 index에 lock을 걸어버리면, 위의 트랜잭션 T2가 INSERT를 할 수 없게 된다.
3. 회복
- 여러 응용이 주기억 장치 버퍼 내의 동일한 데이터베이스 항목을 갱신한 후에 디스크에 기록함으로써 성능을 향상시키는 것이 중요함
- 버퍼의 내용을 디스크에 기록하는 것을 가능하면 최대한 줄이는 것이 일반적 → 버퍼가 꽉 찼을 때 또는 트랜잭션이 완료될 때 버퍼의 내용이 디스크에 기록될 수 있음
- 트랜잭션이 버퍼에는 갱신 사항을 반영했지만 버퍼의 내용이 디스크에 기록되기 전에 고장이 발생할 수 있음
- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행했다면 회복 모듈은 이 트랜잭션의 갱신 사항을 재수행(REDO)하여 트랜잭션의 갱신이 지속성을 갖도록 해야 함
- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행하지 못했다면 원자성을 보장하기 위해 이 트랜잭션이 데이터베이스에 반영했을 가능성이 있는 갱신 사항을 취소(UNDO)해야 함
- 로그가 없으면 아무것도 못하기 때문에 log base recovery라고도 한다.
※ 저장 장치의 유형 (로그가 어디에 저장되어야 하는가, 데이터베이스가 날아가도 로그만 있다면 복구 가능, 로그가 저장되는 디스크가 더 안전해야 한다. 그로 인해 redundant(중복)하게 디스크로 저장하는 방법 채택)
- 주기억 장치와 같은 휘발성 저장 장치에 들어 있는 내용은 시스템이 다운된 후에 모두 사라짐
- 디스크와 같은 비휘발성 저장 장치에 들어있는 내용은 디스크 헤드 등이 손상을 입지 않는 한 시스템이 다운된 후에도 유지됨
- 안전 저장 장치(stable storage)는 모든 유형의 고장을 견딜 수 있는 저장 장치를 의미
- 두 개 이상의 비휘발성 저장 장치가 동시에 고장날 가능성이 매우 낮으므로 비휘발성 저장 장치에 두 개 이상의 사본을 중복해서 저장함으로써 안전 저장 장치를 구현함
① 재해적 고장
- 디스크가 손상을 입어서 데이터베이스를 읽을 수 없는 고장
- 재해적 고장으로부터 회복은 데이터베이스를 백업해 놓은 자기 테이프를 기반으로 함
② 비재해적 고장
- 그 이외의 고장
- 대부분의 회복 알고리즘들은 비재해적 고장에 적용됨
- 로그를 기반으로 한 즉시 갱신, 로그를 기반으로 한 지연 갱신, 그림자 페이징(shadow paging) 등 여러 알고리즘
- 대부분의 상용 DBMS에서 로그를 기반으로 한 즉시 갱신 방식을 사용
- 즉시 갱신 방식은 UNDO 연산이 필요, 하지만 지연 갱신은 갱신 내용이 저장되지 않은 상황이라 UNDO 불필요
※ 로그를 사용한 즉시 갱신
- 즉시 갱신에서는 트랜잭션이 데이터베이스를 갱신한 사항이 주기억 장치의 버퍼에 유지되다가 트랜잭션이 완료되기 전이라도 디스크의 데이터베이스에 기록될 수 있음
- 데이터베이스에는 완료된 트랜잭션의 수행 결과뿐만 아니라 철회된 트랜잭션의 수행 결과도 반영될 수 있음
- 트랜잭션의 원자성과 지속성을 보장하기 위해 DBMS는 로그라고 부르는 특별한 파일을 유지함
- 데이터베이스의 항목에 영향을 미치는 모든 트랜잭션의 연산들에 대해서 로그 레코드를 기록함
- 각 로그 레코드는 로그 순서 번호(LSN: Log Sequence Number)로 식별됨

- 데이터베이스 파일과 로그 파일이 각각 다른 디스크에 들어가는 것은 당연한 것
- 위의 그림에서는 표현되지 않았지만 로그 파일은 이중화되어 저장해야 함
4. Transact-SQL의 트랜잭션
'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 데이터베이스 vs 파일시스템 (0) | 2022.08.12 |
|---|---|
| [데이터베이스] 데이터베이스의 저장과 접근 : 해싱 (0) | 2022.06.20 |
| [데이터베이스] 뷰와 시스템 카탈로그 (0) | 2022.06.18 |
| [데이터베이스] 릴레이션 정규화 (0) | 2022.06.17 |
| [데이터베이스] 물리적 데이터베이스 설계(2) (0) | 2022.06.16 |