[데이터베이스] 인덱스(Index)
2022. 8. 13. 00:19ㆍCS/데이터베이스
※ 인덱스란?
- 인덱스(Index) : 추가적인 쓰기 작업과 저장 공간을 활용해 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
- 데이터베이스에서 테이블의 모든 데이터를 검색하면 시간이 오래 걸릴 수밖에 없기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕는다.
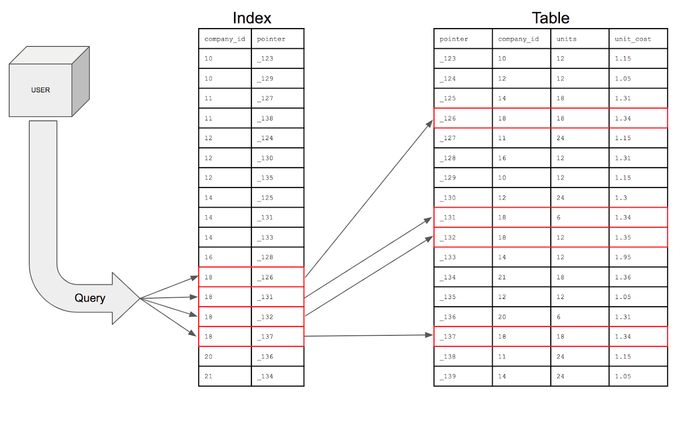
- 인덱스를 활용하게 되면 데이터를 조회하는 SELECT 외에도 UPDATE나 DELETE의 성능이 같이 향상된다.
- 그것이 가능한 이유는 해당 연산을 수행하기 위해 해당 대상을 조회해야만 작업이 가능하기 때문이다.
- 만일, index를 사용하지 않은 컬럼을 조회해야 하는 상황이면 전체를 탐색하는 Full Scan을 수행하게 되는데, 이는 처리 속도가 떨어진다.
※ 인덱스의 관리
- DBMS는 index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색해 올 수 있다.
- 그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행되기 위해서는 다음과 같은 연산이 추가적으로 필요하며 그에 따른 오버헤드가 발생한다.
- INSERT : 새로운 데이터에 대한 인덱스를 추가
- DELETE : 삭제하는 데이터의 인덱스를 사용하지 않겠다는 작업 진행
- UPDATE : 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가
※ 인덱스의 장점과 단점
▷ 장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
▷ 단점
- INSERT, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과를 불러 일으킨다.
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 요구된다.
- 인덱스를 관리하기 위해 추가 작업이 필요하다.
- 만약, 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생하게 되면, 실제 데이터보다 인덱스의 크기가 훨씬 비대해져(기존 인덱스를 삭제하지 않고 사용하지 않음 처리 때문) 오히려 성능이 떨어지게 될 것이다.
※ 인덱스를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
- 0 또는 1 값 밖에 없는 플래그 컬럼이 인덱스인 경우 중복도가 매우 높다.
- 인덱스를 사용하는 것 만큼이나 생성된 인덱스를 관리하는 것도 중요하고, 사용하지 않는 인덱스는 바로 제거를 해주어야 한다.
※ 인덱스 설계
- 인덱스가 늘어날수록 테이블을 갱신할 때 오버헤드가 커지고 디스크 공간이 늘어나므로 최적의 인덱스를 찾는 것이 중요하다.
- 인덱스를 설계한다는 말 자체의 의미는 어떤 컬럼을 조합해서 인덱스를 작성할 것인지, 즉 어떻게 컬럼을 조합해야 조회, 갱신의 모든 성능을 높일 수 있는지에 대한 것이다.
- 다음과 같은 인덱스 설계는 지양하는 것이 좋다.
- 모든 컬럼이 인덱스
- 인덱스에 포함된 컬럼이 한 개 밖에 없는 경우
- 0 또는 1 값 밖에 없는 플래그 컬럼이 인덱스인 경우
※ 인덱스(Index)의 자료구조
1. 해시 테이블(Hash Table)

- 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠른 데이터 검색이 필요할 때 유용하다.
- 해시 테이블은 Key값을 이용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조이다.
- 해시 테이블 기반의 DB 인덱스는 (데이터=컬럼의 값, 데이터의 위치)를 (Key, Value)로 사용하여 컬럼의 값으로 생성된 해시를 통해 인덱스를 구현하였다. 해시 테이블의 시간복잡도는 O(1)이며 매우 빠른 검색을 지원한다.
- 하지만 DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데, 그러한 이유는 해시가 등호(=) 연산에만 특화되었기 때문이다. 해시 함수는 값이 1이라도 달라지면 완전히 다른 해시 값을 생성하는데, 이러한 특성에 의해 부등호 연산(>, <)이 자주 사용되는 데이터베이스 검색을 위해서는 해시 테이블이 적합하지 않다.
- 즉, 예를 들면 "나는"으로 시작하는 모든 데이터를 검색하기 위한 쿼리문은 인덱스의 혜택을 전혀 받지 못하게 된다. 이러한 이유로 데이터베이스의 인덱스에서는 B+Tree가 일반적으로 사용된다.
2. B+Tree
- B+Tree는 DB의 인덱스를 위해 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조이다. B+Tree는 모든 노드에 데이터(Value)를 저장했던 B-Tree와 다른 특성을 가지고 있다.
- 리프노드(데이터 노드)만 인덱스와 함께 데이터(Value)를 가지고 있고, 나머지 노드(인덱스 노드)들은 데이터를 위한 인덱스(Key)만을 갖는다.
- 리프노드들은 LinkedList로 연결되어 있다.
- 데이터 노드 크기는 인덱스 노드의 크기와 같지 않아도 된다.
- 데이터베이스의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생될 수 있다. 이러한 이유로 BTree의 리프노드들을 LinkedList로 연결하여 순차검색을 용이하게 하는 등 BTree를 인덱스에 맞게 최적화하였다.
- 이러한 이유로 비록 B+Tree는 O(logN)의 시간복잡도로 해시 테이블의 시간복잡도보다 그 값이 크지만, 해시 테이블보다 인덱싱에 더욱 적합한 자료구조가 되었다.
아래의 그림은 InnoDB(MySQL을 위한 데이터베이스 엔진)에서 사용된 B+Tree의 구조이다.

- InnoDB에서의 B+Tree는 일반적인 구조보다 더욱 복잡하게 구현이 되었다. InnoDB에서는 같은 레벨의 노드들끼리는 Linked List가 아닌 Double Linked List로 연결되었으며, 자식 노드들은 Single Linked List로 연결되어 있다.
[출처]
'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 트랜잭션(Transaction)이란 (0) | 2022.08.13 |
|---|---|
| [데이터베이스] 정규화 (1차, 2차, 3차, BCNF) (0) | 2022.08.13 |
| [데이터베이스] 데이터베이스 키(key)의 개념 및 종류 (0) | 2022.08.12 |
| [데이터베이스] 커넥션 풀이란? (Connection Pool) (0) | 2022.08.12 |
| [데이터베이스] 데이터베이스 vs 파일시스템 (0) | 2022.08.12 |