2022. 8. 16. 21:16ㆍCS/자료구조
배열과 메모리
배열
배열(array)는 같은 타입의 변수들로 이루어진 유한 집합으로 정의된다. 배열을 구성하는 각각의 값을 요소(element)라고 하며, 배열에서의 위치를 가리키는 숫자는 인덱스(index)라고 한다.
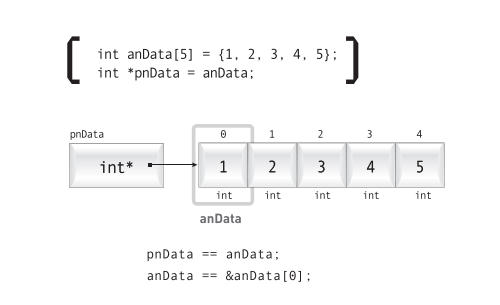
배열을 이루는 각 요소에 부여된 인덱스는 0으로 시작한다. 첫 번째 요소의 인덱스가 1이 아니라 0이된 이유는 배열의 인덱스는 첫 번째 요소를 기준으로 얼마만큼 떨어져 있는지 상대적인 값으로 표현하기 때문이다.
위의 그림에서 볼 수 있는 anData는 배열의 이름이며 동시에 인덱스가 0인 첫 번째 요소의 주소가 된다. 배열의 이름도 변수의 이름처럼 식별자이긴 하나 그 실체는 변수가 아니라 메모리의 주소 상수이다.
만약, anData의 실제 값이 0x0012FF60이라고 가정한다면, 두 번째 요소의 메모리 주소는 0x0012FF64가 된다. 왜냐하면, int형 메모리의 크기가 4바이트이고 배열을 이루는 각 요소들의 메모리가 모두 이어져있기 때문이다.
C언어에서는 배열 선언만 하고 초기화하지 않는다면 각 배열 요소에는 쓰레기값이 저장되어 있게 된다. 따라서 초기화되지 않은 배열은 사용하지 않도록 주의해야 한다.
다차원 배열
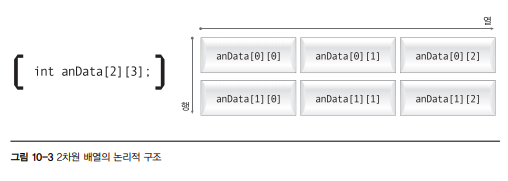
다차원 배열은 배열의 배열을 선언하여 중첩하는 것을 의미한다. 1차원 배열이 논리적으로 직선 모양이라면, 2차원 배열은 사각형이 되고 3차원 배열은 육면체와 같은 모양을 한다.
2차원 배열은 1차원 배열과는 달리 두 개의 인덱스(행과 열)가 존재한다. 만일 2차원 배열의 요소가 6개라고 가정한다면, 위 그림과 같이 2행 3열의 논리적인 구조를 생각할 수 있다. 따라서 한 요소를 식별하라면 두 개의 인덱스가 필요하다.
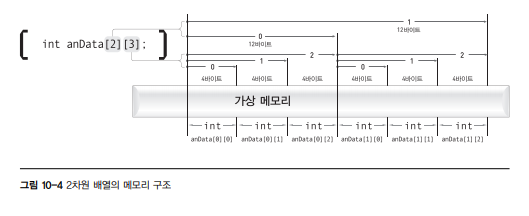
그러나, 논리적인 구조와는 달리 2차원 배열의 실제 메모리를 구조적으로 살펴보면 1차원 배열과 마찬가지로 전체 요소들의 메모리가 선형으로 모두 인접해있음을 알 수 있다. 이런 이유로 다차원 배열의 모든 요소도 1차원 배열처럼 접근할 수 있다.
그리고 단순히 메모리의 크기만 놓고 생각한다면 요소의 개수가 6인 1차원 배열과 2행 3열인 2차원 배열의 크기는 완전히 같다.
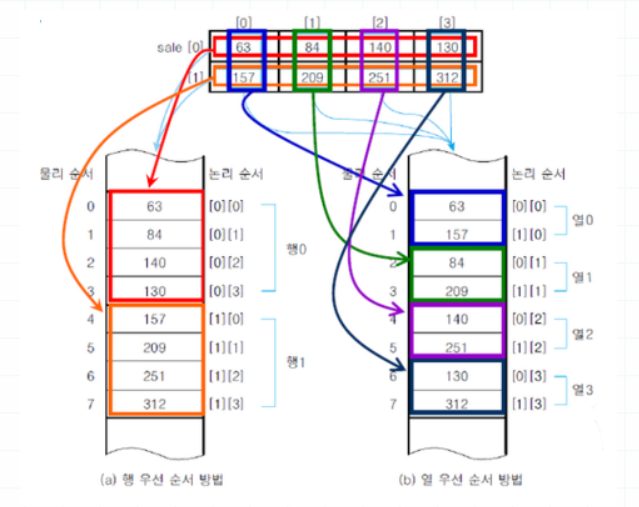
실제로 메모리에 저장될 때 첫 번째 인덱스인 행을 기준으로 하는 행 우선 순서 방법과 열을 기준으로 하는 열 우선 순서 방법이 존재한다.
배열의 특징
- 같은 타입의 데이터를 나열한 선형 자료구조(sequence container)
- 선형 자료구조 : 하나의 자료 뒤에 하나의 자료가 존재하는 것
- 연속된 메모리 공간에 순차적으로 저장
- 논리적 저장 순서와 물리적 저장 순서가 일치한다.
- 생성할 때 데이터를 저장하는데 필요한 메모리를 한 번에 확보해서 사용한다.
- 배열의 크기는 고정, 선언할 때 배열의 크기를 정하고 변경할 수 없다.
삭제
배열의 원소를 삭제할 경우 삭제한 원소보다 큰 인덱스의 값을 갖는 원소들을 1씩 옮겨줘야 하기 때문에 시간 복잡도는 O(n) 이다.
삽입
배열의 원소를 삽입할 경우 전제 조건은 배열에 빈 칸이 있다는 것이다. 빈 칸이 없다면 요소를 삽입할 때 삽입할 공간이 부족하기 때문에 새로운 배열을 선언하고, 기존 배열의 값을 새로운 배열에 복사한 뒤 N+1번째 요소를 삽입한다. 이후, 기존 배열을 가리키던 변수가 새로운 배열을 가리키도록 한다.
이 과정을 거치면 아래와 같은 부작용이 있다.
- 새로운 크기의 배열을 선언하는 과정에서 메모리를 소모하게 된다.
- 이전 배열에서 새로운 배열로 값을 복사하는 과정에서 시간이 소요된다.
- 기존 배열을 참조하고 있던 다른 변수들의 참조는 변경되지 않기 때문에 여전히 이전 배열을 가리키고 있다.
정리하면,
- 배열의 크기가 충분할 때는 O(1)
- 배열에 여유 공간이 없을 경우 위의 방식으로 배열 확장이 필요하므로 O(N)
시간복잡도
- 삽입/삭제
- 배열의 맨 앞에 삽입/삭제하는 경우 : O(n)
- 배열의 맨 뒤에 삽입/삭제하는 경우 : O(1)
- 배열의 중간에 삽입/삭제하는 경우 : O(n)
- 탐색
- O(1)
장점
- 인덱스를 통해 모든 데이터에 직접 액세스하기 때문에 액세스 속도가 빠르다.
- 리스트나 그래프와 같은 자료구조 형태와 달리 탐색 없이 인덱스를 통해 액세스 (속도 빠름)
- 리스트의 경우 10,000번째 값을 액세스하기 위해 첫 번째 값부터 10,000번 탐색해야 하지만 배열의 경우 인덱스 위치의 주소값을 얻는 단 한 번의 연산만으로 액세스가 가능하다. 자료구조의 크기가 크면 클수록 이 차이는 커진다.
- 포인터 등 부가적인 정보가 없어 기록 밀도가 1이다.
- 리스트, 그래프 등은 데이터 외에 포인터 등의 부가정보를 가지기 때문에 기록밀도가 1이 되지 않지만, 배열은 부가정보 없이 데이터만 저장하기 때문에 기록밀도가 1이다.
- 리스트나 그래프는 메모리에 분산시켜 데이터를 저장하고 포인터로 연결시킨 형태라 데이터 외 부가정보를 가지게 된다. 반대로 배열은 메모리의 연속된 공간에 데이터를 저장하고, 인덱스를 이용한 연산을 통해 액세스하기 때문에 부가정보가 필요 없다.
- 가장 간단하며 사용하기 쉽다.
단점
- 삽입과 삭제가 어렵고 오래 걸린다.
- 원소를 삽입하거나 삭제할 경우, 해당 원소 이후의 모든 원소들을 한 칸씩 밀거나 당겨야 한다. (연속된 메모리 공간에 저장된다는 특성 때문)
- 배열의 크기를 바꿀 수 없다.
- 배열은 처음 생성할 때 크기를 설정함
- 크기를 변경하기 위해서는 원하는 크기의 새로운 배열을 선언한 뒤 값을 복사해야 한다.
- 연속된 메모리라서 공간 낭비가 발생
- 중간에 데이터가 삭제되면 공간 낭비가 발생할 수 있고, 처음에 배열의 크기를 100으로 설정했는데 10 정도밖에 쓰지 않으면 나머지 공간은 빈 공간으로 낭비가 발생한다.
C++에서 Vector와 Array의 차이
- vector는 크기가 가변적임
- vector가 크기를 가변적으로 변경할 수 있는 이유는?
- vector는 처음 선언될 때, 벡터의 크기가 커질 수 있는 것을 고려하여 약간 여분이 있는 배열을 할당한다
- 만약, 할당된 배열의 크기를 넘어서는 데이터들이 들어오게 되면, 새로운 배열 공간을 마련해 기존의 배열을 재할당하는 과정을 거치게 된다
+++ Java List Collection
ArrayList
일반 배열과 ArrayList는 인덱스로 객체를 관리한다는 점에서 동일하지만, 크기를 동적으로 늘릴 수 있다는 점에서 차이점이 있다.ArrayList는 내부에서 처음 설정한 저장 용량(capacity)가 있다. 설정한 저장 용량 크기를 넘어서 더 많은 객체가 들어오게 되면, 배열 크기를 1.5배로 증가시킴
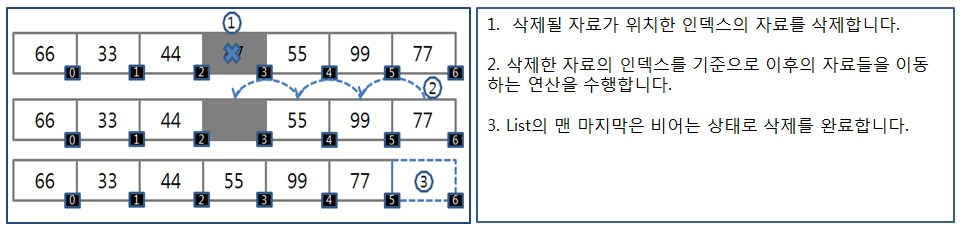
ArrayList에서 특정 인덱스의 객체를 제거하게 되면, 제거한 객체의 인덱스부터 마지막 인덱스까지 모두 앞으로 1칸씩 앞으로 이동한다. 객체를 추가하게 되면 1칸씩 뒤로 이동하게 된다. 인덱스 값을 유지하기 위해서 전체 객체가 위치가 이동한다.
따라서 잦은 원소의 이동, 삭제가 발생할 경우 ArrayList보다 LinkedList를 사용하는 것이 좋다.
배열과 ArrayList의 차이
- 배열은 크기가 고정되어있지만 ArrayList는 사이즈가 동적인 배열이다.
- 배열은 primitive type(int, byte, char 등)과 Object 모두를 담을 수 있지만, arrayList는 Object element만 담을 수 있다.
- 배열은 제네릭을 사용할 수 없지만, ArrayList는 타입 안정성을 보장해주는 제네릭을 사용할 수 있다.
- 길이에 대해 배열은 length 변수를 쓰고, ArrayList는 size() 메서드를 써야한다.
- 배열은 element들을 할당하기 위해 assignment(할당) 연산자를 써야하고, arrayList는 add() 메서드를 통해 element를 삽입한다.
ArrayList의 삽입/삭제 과정

LinkedList
노드 간에 연결(link)을 통해서 리스트로 구현된 객체이다. 다음 노드의 위치 정보만 가지고 있으며 인덱스를 가지고 있지 않기 때문에 탐색시 순차접근만 가능 (노트 탐색 시 시간이 많이 소요될 수 있음) (randomAccess 불가)
노드 추가/삭제는 위치정보의 수정만으로 가능하기 때문에 성능이 좋음
LinkedList는 ArrayList와는 달리 List 인터페이스를 구현한 AbstractList를 상속하지 않고 AbstractSequentialList를 상속한다.

LinkedList의 삽입/삭제 과정


Vector
Vector는 ArrayList와 동일한 내부 구조를 가지고 있다. Vector 객체를 생성하기 위해서는 저장할 타입을 지정해야 한다.
ArrayList와 차이점으로는 Vector 클래스는 동기화된(synchronized) 메서드로 구성되어 있다. 그렇기 때문에 멀티 스레드 환경에서 안전하게 객체를 추가, 삭제할 수 있다.(Thread Safe)
다만 동기화되어 있기 때문에 ArrayList 보다는 객체를 추가, 삭제하는 과정은 느릴수 밖에 없다.(trade off)
데이터 추가 시 공간이 부족한 경우 배열 크기를 2배로 증가시킨다.
ArrayList : 객체 검색, 맨 마지막 인덱스에 객체 추가에 좋은 성능을 발휘함
LinkedList : 객체 삽입 및 삭제에 좋은 성능을 발휘함
Vector: 멀티스레드 환경에서 사용
[출처]
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] Red-Black Tree (0) | 2022.10.07 |
|---|---|
| [자료구조] 이진 탐색 트리 (Binary Search Tree) (0) | 2022.08.18 |
| [자료구조] Heap (0) | 2022.08.18 |
| [자료구조] Hash (0) | 2022.08.18 |